2.2 Лекция - Реализация файловой системы.
- Просмотреть
Литература
- Современные операционные системы, Э. Таненбаум, 2002, СПб, Питер, 1040 стр., (в djvu 10.1Мбайт) подробнее>>
- Сетевые операционные системы Н. А. Олифер, В. Г. Олифер (в zip архиве 1.1Мбайт)
- Сетевые операционные системы Н. А. Олифер, В. Г. Олифер, 2001, СПб, Питер, 544 стр., (в djvu 6.3Мбайт) подробнее>>
2.1 Структура файловой системы
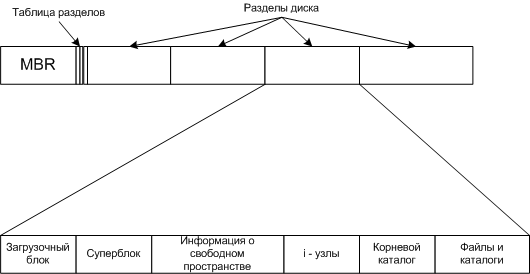
Возможная структура файловой системы
Все что до "Загрузочного блока" и включая его одинаково у всех ОС. Дальше начинаются различия.
Суперблок - содержит ключевые параметры файловой системы.
2.2 Реализация файлов
Основная проблема - сколько, и какие блоки диска принадлежат тому или иному файлу.
2.2.1 Непрерывные файлы
Выделяется каждому файлу последовательность соседних блоков.
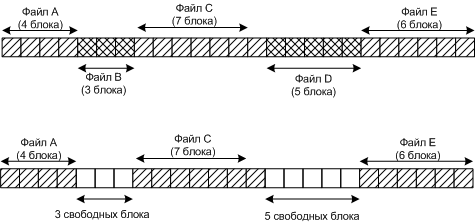
5 непрерывных файлов на диске и состояние после удаления двух файлов
Преимущества такой системы:
-
Простота - нужно знать всего два числа, это номер первого блока и число блоков.
-
Высокая производительность - требуется только одна операция поиска, и файл может быть прочитан за одну операцию
Недостатки:
-
Диск сильно фрагментируется
Сейчас такая запись почти не используется, только на CD-дисках и магнитных лентах.
2.2.2 Связные списки
Файлы хранятся в разных не последовательных блоках, и с помощью связных списков можно собрать последовательно файл.

Размещение файла в виде связного списка блоков диска
Номер следующего блока хранится в текущем блоке.
Преимущества:
-
Нет потерь дискового пространства на фрагментацию
-
Нужно хранить информацию только о первом блоке
Недостатки:
-
Уменьшение быстродействия - для того чтобы получить информацию о всех блоках надо перебрать все блоки.
-
Уменьшается размер блока из-за хранения служебной информации
2.2.3 Связные списки при помощи таблиц в памяти
Чтобы избежать два предыдущих недостатка, стали хранить всю информацию о блоках в специальной таблице загружаемой в память.
FAT (File Allocation Table) - таблица размещения файлов загружаемая в память.
Рассмотри предыдущий пример, но в виде таблицы.
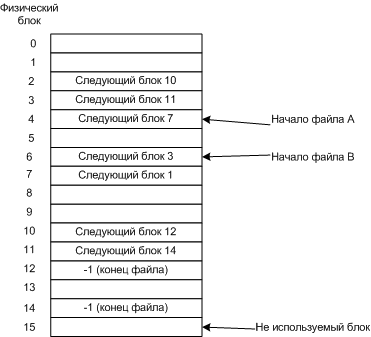
Таблица размещения файлов
Здесь тоже надо собирать блоки по указателям, но работает быстрее, т.к. таблица загружена в память.
Основной не достаток этого метода - всю таблицу надо хранить в памяти. Например, для 20Гбайт диска, с блоком 1Кбайт (20 млн. блоков), потребовалась бы таблица в 80 Мбайт (при записи в таблице в 4 байта).
Такие таблицы используются в MS-DOS и Windows.
2.2.4 i - узлы
С каждым файлом связывается структура данных, называемая i-узлом (index-node- индекс узел), содержащие атрибуты файла и адреса всех блоков файла.
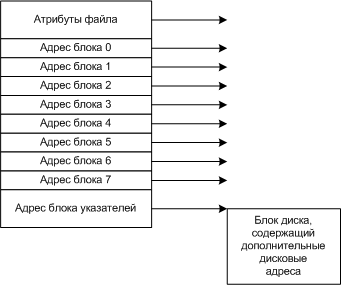
Примеры i-узла
Преимущества:
-
Быстродействие - имея i-узел можно получить информацию о всех блоках файла, не надо собирать указатели.
-
Меньший объем, занимаемый в памяти. В память нужно загружать только те узлы, файлы которых используются.
Если каждому файлу выделять фиксированное количество адресов на диске, то со временем этого может не хватить, поэтому последняя запись в узле является указателем на дополнительный блок адресов и т.д..
Такие узлы используются в UNIX.
2.3 Реализация каталогов
При открытии файла используется имя пути, чтобы найти запись в каталоге. Запись в каталоге указывает на адреса блоков диска.
В зависимости от системы это может быть:
-
дисковый адрес всего файла (для непрерывных файлов)
-
номер первого блока (связные списки)
-
номер i-узла
Одна из основных задач каталоговой системы преобразование ASCII-имени в информацию, необходимую для нахождения данных.
Также она хранит атрибуты файлов.
Варианты хранения атрибутов:
-
В каталоговой записи (MS-DOS)
-
В i-узлах (UNIX)
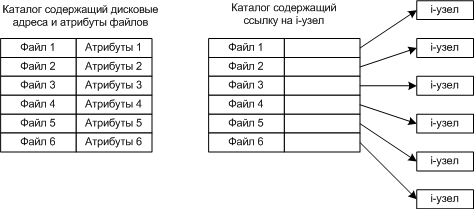
Варианты реализации каталогов
2.3.1 Реализация длинных имен файлов
Раньше операционные системы использовали короткие имена файлов, MS-DOS до 8 символов, в UNIX Version 7 до 14 символов. Теперь используются более длинные имена файлов (до 255 символов и больше).
Методы реализации длинных имен файлов:
-
Просто выделить место под длинные имена, увеличив записи каталога. Но это займет много места, большинство имен все же меньше 255.
-
Применить записи с фиксированной частью (атрибуты) и динамической записью (имя файла).
Второй метод можно реализовать двумя методами:
-
Имена записываются сразу после заголовка (длина записи и атрибутов)
-
Имена записываются в конце каталога после всех заголовков (указателя на файл и атрибутов)
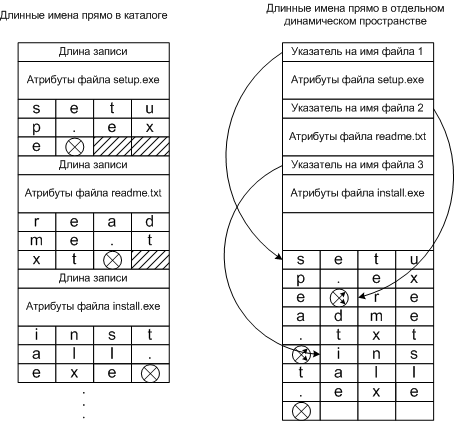
Реализация длинных имен файлов
2.3.2 Ускорение поиска файлов
Если каталог очень большой (несколько тысяч файлов), последовательное чтение каталога мало эффективно.
2.3.2.1 Использование хэш-таблицы для ускорения поиска файла.
Алгоритм записи файла:
-
Создается хэш-таблица в начале каталога, с размером n (n записей).
-
Для каждого имени файла применяется хэш-функция, такая, чтобы при хэшировании получалось число от 0 до n-1.
-
Исследуется элемент таблицы соответствующий хэш-коду.
-
Если элемент не используется, туда помещается указатель на описатель файла (описатели размещены вслед за хэш-таблицей).
-
Если используется, то создается связный список, объединяющие все описатели файлов с одинаковым хэш-кодом.
Алгоритм поиска файла:
-
Имя файла хэшируется
-
По хэш-коду определяется элемент таблицы
-
Затем проверяются все описатели файла из связного списка и сравниваются с искомым именем файла
-
Если имени файла в связном списке нет, это значит, что файла нет в каталоге.
Такой метод очень сложен в реализации, поэтому используется в тех системах, в которых ожидается, что каталоги будут содержать тысячи файлов.
2.3.2.2 Использование кэширования результатов поиска файлов для ускорения поиска файла.
Алгоритм поиска файла:
-
Проверяется, нет ли имени файла в кэше
-
Если нет, то ищется в каталоге, если есть, то берется из кэша
Такой способ дает ускорение только при частом использовании одних и тех же файлов.
2.4 Совместно используемые файлы
Иногда нужно чтобы файл присутствовал в разных каталогах.
Link (связь, ссылка) - с ее помощью обеспечивается присутствие файла в разных каталогах.
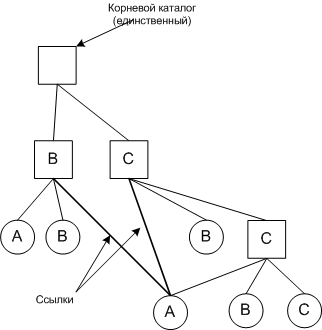
А - совместно используемый файл.
Такая файловая система называется ориентированный ациклический граф (DAG, Directed Acyclic Graph).
Возникает проблема, если дисковые адреса содержатся в самих каталоговых записях, тогда при добавлении новых данных к совместно используемому файлу новые блоки будут числится только в каталоге того пользователя, который производил эти изменения в файле.
Есть два решения этой проблемы:
-
Использование i-узлов, в каталогах хранится только указатель на i-узел. Такие ссылки называются жесткими ссылками.
-
При создании ссылки, в каталоге создавать реальный Link-файл, новый файл содержит имя пути к файлу, с которым он связан. Такие ссылки называются символьными ссылками.
2.4.1 Жесткие ссылки
Может возникнуть проблема, если владелец файла удалит его (и i-узел тоже), то указатель, каталога содержащего ссылку, будет указывать на не существующий i-узел. Потом может появиться i-узел с тем же номером, а значит, ссылка будет указывать на не существующий файл.
Поэтому в этом случае при удалении файла i-узел лучше не удалять.
Файл будет удален только после того, как счетчик будет равен 0.
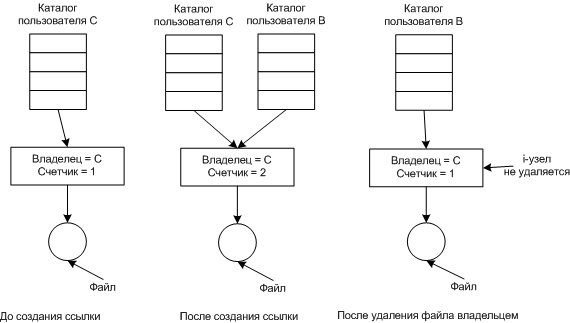
Иллюстрация проблемы, которая может возникнуть
2.4.2 Символьные ссылки
Удаление файла не влияет на ссылку, просто по ссылке будет не возможно найти файл (путь будет не верен).
Удаление ссылки тоже никак не скажется на файле.
Но возникают накладные расходы, чтобы получить доступ к i-узлу, должны быть проделаны следующие шаги:
-
Прочитать файл-ссылку (содержащий путь)
-
Пройти по всему этому путь, открывая каталог за каталогом
2.5 Организация дискового пространства
2.5.1 Размер блока
Если принято решение хранить файл в блоках, то возникает вопрос о размере этих блоков.
Есть две крайности:
-
Большие блоки - например, 1Мбайт, то файл даже 1 байт займет целый блок в 1Мбайт.
-
Маленькие блоки - чтение файла состоящего из большого числа блоков будет медленным.
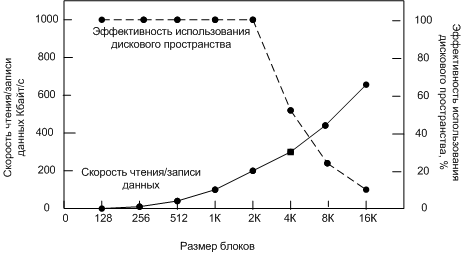
Скорости чтения/записи и эффективность использования диска,
в системе с файла одинакового размера 2 Кбайта.
В UNIX системах размер блока фиксирован, и, как правило, равен от 1Кбайта до 4Кбайт.
В MS-DOS размер блока может быть от 512 до 32 Кбайт в зависимости от размера диска, поэтому FAT16 использовать на дисках больше 500 Мбайт не эффективно.
В NTFS размер блока фиксирован (от 512байт до 64 Кбайт), как правило, равен примерно 2Кбайтам (от 512байт до 64 Кбайт).
2.5.2 Учет свободных блоков
Основные два способа учета свободных блоков :
-
Связной список блоков диска, в каждом блоке содержится номеров свободных блоков столько, сколько вмешается в блок. Часто для списка резервируется нужное число блоков в начале диска.
Недостатки:
- Требует больше места на диске, если номер блока 32-разрядный, требуется 32бита для номера
- Излишние операции ввода/вывода, т.к. в памяти не хранятся все блоки, а, например, только один блок -
Битовый массив (бит-карта) - для каждого блока требуется один бит.
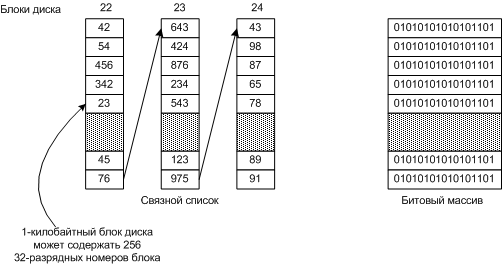
Основные два способа учета свободных блоков
2.5.3 Дисковые квоты
Чтобы ограничить пользователя, существует механизм квот.
Два вида лимитов:
-
Жесткие - превышены быть не могут
-
Гибкие - могут быть превышены, но при выходе пользователь должен удалить лишние файлы. Если он не удалил, то при следующем входе получит предупреждение, после получения нескольких предупреждений он блокируется.
Наиболее распространенные квоты:
-
Объем использования диска
-
Количество файлов
-
Количество открытых файлов
2.6 Надежность файловой системы
2.6.1 Резервное копирование
Случаи, для которых необходимо резервное копирование:
-
Аварийные ситуации, приводящие к потере данных на диске
-
Случайное удаление или программная порча файлов
Основные принципы создания резервных копий:
-
Создавать несколько копий - ежедневные, еженедельные, ежемесячные, ежеквартальные.
-
Как правило, необходимо сохранять не весь диск, а только выборочные каталоги.
-
Применять инкрементные резервные копии - сохраняются только измененные файлы
-
Сжимать резервные копии для экономии места
-
Фиксировать систему при создании резервной копии, чтобы вовремя резервирования система не менялась.
-
Хранить резервные копии в защищенном месте, не доступном для посторонних.
Существует две стратегии:
-
Физическая архивация - поблочное копирование диска (копируются блоки, а не файлы)
Недостатки:
- копирование пустых блоков
- проблемы с дефектными блоками
- не возможно применять инкрементное копирование
- не возможно копировать отдельные каталоги и файлы
Преимущества:
- высокая скорость копирования
- простота реализации -
Логическая архивация - работает с файлами и каталогами. Применяется чаще физической.
2.6.2 Непротиворечивость файловой системы
Если в системе произойдет сбой, прежде чем модифицированный блок будет записан, файловая система может попасть в противоречивое состояние. Особенно если это блок i-узла, каталога или списка свободных блоков.
В большинстве файловых систем есть специальная программа, проверяющая непротиворечивость системы.
В UNIX - fsck.
В Windows - scandisk.
Если произошел сбой, то во время загрузки они проверяют файловую систему (если файловая система журналируемая, такая проверка не требуется).
Журналируемая файловая система - операции выполняются в виде транзакций, если транзакция не завершена, то во время загрузки происходит откат в системе назад.
Два типа проверки на непротиворечивость системы:
-
проверка блоков - проверяется дублирование блоков в файле или в списке свободных блоков. Потом проверяется, нет ли блока файла, который еще присутствует в списке свободных блоков. Если блока нет в занятых и в незанятых, то блок считается не достающем (уменьшается место на диске), такие блоки добавляются к свободным. Также блок может оказаться в двух файлах.
-
проверка файлов - в первую очередь проверяется каталоговая структура. Файл может оказаться; либо в нескольких каталогах, либо не в одном каталоге (уменьшается место на диске).
2.7 Производительность файловой системы
Так как дисковая память достаточно медленная. Приходится использовать методы повышающие производительность.
2.7.1 Кэширование
Блочный кэш (буферный кэш) - набор блоков хранящиеся в памяти, но логически принадлежащие диску.
Перехватываются все запросы чтения к диску, и проверяется наличие требуемых блоков в кэше.
Ситуация схожа со страничной организацией памяти, можно применять те же алгоритмы.
Нужно чтобы измененные блоки периодически записывались на диск.
В UNIX это выполняет демон update (вызывая системный вызов sync).
В MS-DOS модифицированные блоки сразу записываются на диск (сквозное кэширование).
2.7.2 Опережающее чтение блока
Если файлы считываются последовательно, и когда получен к-блок, можно считать блок к+1 (если его нет в памяти). Что увеличивает быстродействие.
2.7.3 Снижение времени перемещения блока головок
Если записывать, наиболее часто запрашиваемые файлы, рядом (соседние сектора или дорожки), то перемещение головок будет меньше
В случае использования i-узлов если они расположены в начале диска, то быстродействие будет уменьшено, т.к. сначала головка считает i-узел (в начале диска), а потом будет считывать данные (где-то на диске). Если располагать i-узлы поближе к данным, то можно увеличить скорость доступа.