3.2 Лекция - Примеры файловых систем. UNIX V7; BSD; Linux (EXT2; EXT3; RFS; JFS; XFS); NFS.
- Просмотреть
Литература
- Современные операционные системы, Э. Таненбаум, 2002, СПб, Питер, 1040 стр., (в djvu 10.1Мбайт) подробнее>>
- Сетевые операционные системы Н. А. Олифер, В. Г. Олифер (в zip архиве 1.1Мбайт)
- Сетевые операционные системы Н. А. Олифер, В. Г. Олифер, 2001, СПб, Питер, 544 стр., (в djvu 6.3Мбайт) подробнее>>
3.1 Файловая система UNIX V7
Хотя это старая файловая система основные элементы используются и современных UNIX системах.
Особенности:
-
Имена файлов ограничены 14 символами ASCII, кроме косой черты "/" и NUL - отсутствие символа. (в последующих версиях расширены до 255)
-
Поддержка ссылок.
-
Контроль доступа к файлам и каталогам.
-
Имена чувствительны к регистру, my.txt и MY.TXT это разные файлы.
-
Используется схема i-узлов.
-
Не делается различий между разными файлами (текстовыми, двоичными и д.р.).
-
Поддерживаются символьные специальные файлы (для символьных устройств ввода-вывода).
- Если открыть файл /dev/lp и записать в него данные, то данные будут распечатаны на принтере.
- Если открыть файл /dev/tty и прочитать из него данные, то получим данные, введенные с клавиатуры. -
Поддерживаются блочные специальные файлы (для блочных устройств ввода-вывода, например /dev/hd1).
-
Позволяет монтировать разделы в любое место дерева системы.

Расположение файловой системы UNIX
Суперблок содержит:
-
Количество i-узлов
-
Количество дисковых блоков
-
Начало списка свободных блоков диска
При уничтожении суперблока, файловая система становится не читаемой.
Каждый i-узел имеет 64 байта в длину и описывает один файл (в том числе каталог).
Каталог содержит по одной записи для каждого файла.
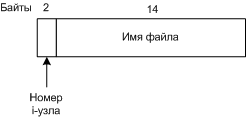
Каталоговая запись UNIX V7 в 16 байт
Структура i-узела
|
Поле |
Байты |
Описание |
| Mode | 2 | Тип файла, биты защиты, биты setuid и setgid |
| Nlinks | 2 | Количество каталоговых записей, указывающий на этот i-узел |
| Uid | 2 | Идентификатор владельца |
| Gid | 2 | Номер группы |
| Size | 4 | Размер файла в байтах |
| Addr | 39 | Адрес первых 10 дисковых блоков файла и 3 косвенных блока |
| Gen | 1 | Счетчик использования i-узла |
| Atime | 4 | Время последнего доступа файла |
| Mtime | 4 | Время последнего изменения файла |
| Ctime | 4 | Время последнего изменения i-узла |
Первые 10 дисковых блоков файла хранятся в самом i-узле, при блоке в 1Кбайт, файл может быть 10Кбайт.
Дополнительные блоки для i-узла, в случае больших файлов:
-
Одинарный косвенный блок - дополнительный блок с адресами блоков файла, если файл не сильно большой, то один из адресов в i-узле указывает на дополнительный блок с адресами. Файл может быть 266Кбайт=10Кбайт+256Кбайт (256Кбайт <= 256 (2^8)-адресов блоков = 1Кбайт-размер блока / 4байта-размер адреса)
-
Двойной косвенный блок - дополнительный блок с адресами одинарных косвенных блоков, если одного дополнительного блока не хватает. Файл может быть 65Мбайт=10Кбайт+2^8Кбайт+2^16Кбайт.
-
Тройной косвенный блок - дополнительный блок с адресами двойных косвенных блоков, если одного одинарного косвенного блока не хватает. Файл может быть 16Гбайт=10Кбайт+2^8Кбайт+2^16Кбайт+2^24Кбайт.

i-узел UNIX V7
3.1.1 Поиск файла
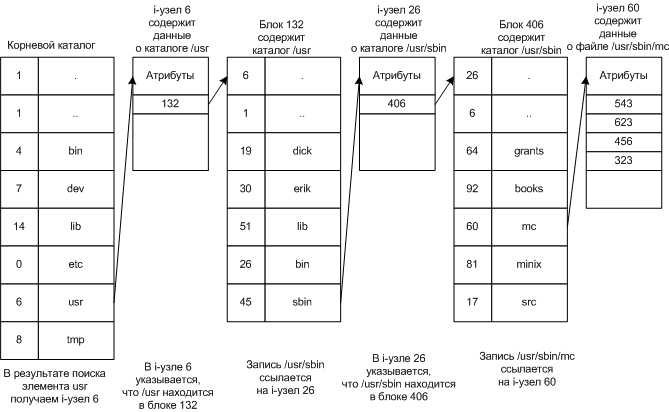
Этапы поиска файла по абсолютному пути /usr/sbin/mc
При использовании относительного пути, например sbin/mc, поиск начинается с рабочего каталога /usr.
3.1.2 Блокировка данных файла
Блокирование осуществляется по блочно.
Стандартом POSIX два типа блокировки:
-
Блокировка с монополизацией - больше ни один процесс эти блоки заблокировать не может.
-
Блокировка без монополизации - могут блокировать и другие процессы.

Блокировки данных файла без монополизации
Если процесс К попытается блокировать блок 6 с монополизацией, то сам процесс будет заблокирован до разблокирования блока 6 всеми процессами.
3.1.3 Создание и работа с файлом
fd=creat("abc", mode) - Пример создания файла abc с режимом защиты, указанном в переменной mode (какие пользователи имеют доступ). Используется системный вызов creat.
Успешный вызов возвращает целое число fd - дескриптор файла.
Который хранится в таблице дескрипторов файла, открывшего процесса.
После этого можно работать с файлом, используя системные вызовы write и read.
n=read(fd, buffer, nbytes)
n=write(fd, buffer, nbytes)
У обоих вызовов всего по три параметра:
-
fd - дескриптор файла, указывающий на открытый файл
-
buffer - адрес буфера, куда писать или откуда читать данные
-
nbytes - счетчик байтов, сколько прочитать или записать байт
Теперь нужно по дескриптору получить указатель на i-узел и указатель на позицию в файле для записи или чтения.
Таблица открытых файлов - создана для хранения указателей на i-узел и на позицию в файле. И позволяет родительскому и дочернему процессам совместно использовать один указатель в файле, но для посторонних процессов выделять отдельные указатели.
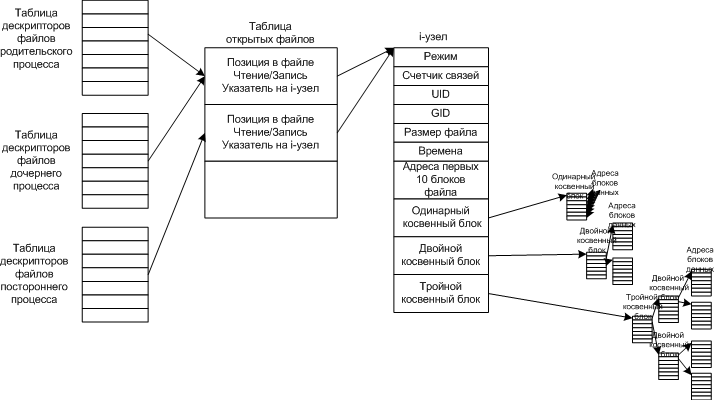
Связь между таблицей дескрипторов файлов, таблицей открытых файлов и таблицей i-узлов.
3.2 Файловая система BSD
Основу составляет классическая файловая система UNIX.
Особенности (отличие от предыдущей системы):
-
Увеличена длина имени файла до 255 символов
-
Реорганизованы каталоги
-
Было добавлено кэширование имен файлов, для увеличения производительности.
-
Применено разбиение диска на группы цилиндров, чтобы i-узлы и блоки данных были поближе друг к другу, для каждой группы были свои:
- суперблок
- i-узлы
- блоки данных.
Это сделано для уменьшения перемещений галовок. -
Используются блоки двух размеров, для больших файлов использовались большие блоки, для маленьких маленькие.
Каталоговые записи ни как не отсортированы и следуют друг за другом.

Каталог BSD с тремя каталоговыми записями для трех файлов и тот же каталог после удаления файла zip, увеличивается длина первой записи.
3.3 Файловые системы LINUX
Изначально использовалась файловая система MINIX с ограничениями: 14 символов для имени файла и размер файла 64 Мбайта.
После была создана файловая система EXT с расширением: 255 символов для имени файла и размер файла 2Гбайта.
Система была достаточно медленной.
3.3.1 Файловая система EXT2
Эта файловая система стала основой для LINUX, она очень похожа BSD систему.
Вместо групп цилиндров используются группы блоков.

Размещение файловой системы EXT2 на диске
Другие особенности:
-
Размер блока 1 Кбайт
-
Размер каждого i-узла 128 байт.
-
i-узел содержит 12 прямых и 3 косвенных адресов, длина адреса в i-узле стала 4 байта, что обеспечивает поддержку размера файла чуть более 16Гбайт.
Особенности работы файловой системы:
-
Создание новых каталогов распределяется равномерно по группам блоков, чтобы в каждой группе было одинаковое количество каталогов.
-
Новые файлы старается создавать в группе, где и находится каталог.
-
При увеличении файла система старается новые блоки записывать ближе к старым.
Благодаря этому файловую систему не нужно дефрагментировать, она не способствует фрагментации файлов (в отличии от NTFS), что проверено многолетним использованием.
3.3.2 Файловая система EXT3
В отличие от EXT2, EXT3 является журналируемой файловой системой, т.е. не попадет в противоречивое состояние после сбоев. Но она полностью совместима с EXT2.
Разработанная в Red Hat
В данный момент является основной для LINUX.
Драйвер Ext3 хранит полные точные копии модифицируемых блоков (1КБ, 2КБ или 4КБ) в памяти до завершения операции. Это может показаться расточительным. Полные блоки содержат не только изменившиеся данные, но и не модифицированные.
Такой подход называется "физическим журналированием", что отражает использование "физических блоков" как основную единицу ведения журнала. Подход, когда хранятся только изменяемые байты, а не целые блоки, называется "логическим журналированием" (используется XFS). Поскольку ext3 использует "физическое журналирование", журнал в ext3 имеет размер больший, чем в XFS. За счет использования в ext3 полных блоков, как драйвером, так и подсистемой журналирования нет сложностей, которые возникают при "логическом журналировании".
Типы журналирования поддерживаемые Ext3, которые могут быть активированы из файла /etc/fstab:
-
data=journal (full data journaling mode) - все новые данные сначала пишутся в журнал и только после этого переносятся на свое постоянное место. В случае аварийного отказа журнал можно повторно перечитать, приведя данные и метаданные в непротиворечивое состояние.
Самый медленный, но самый надежный. -
data=ordered - записываются изменения только мета-данных файловой системы, но логически metadata и data блоки группируются в единый модуль, называемый transaction. Перед записью новых метаданных на диск, связанные data блоки записываются первыми. Этот режим журналирования ext3 установлен по умолчанию.
При добавлении данных в конец файла режимdata=orderedгарантированно обеспечивает целостность (как при full data journaling mode). Однако если данные в файл пишутся поверх существующих, то есть вероятность перемешивания "оригинальных" блоков с модифицированными. Это результат того, чтоdata=orderedне отслеживает записи, при которых новый блок ложится поверх существующего и не вызывает модификации метаданных. -
data=writeback (metadata only) - записываются только изменения мета-данных файловой системы. Самый быстрый метод журналирования. С подобным видом журналирования вы имеете дело в файловых системах XFS, JFS и ReiserFS.
3.3.3 Файловая система XFS
XFS - журналируемая файловая система разработанная Silicon Graphics, но сейчас выпущенная открытым кодом (open source).
Официальная информация на http://oss.sgi.com/projects/xfs/
XFS была создана в начале 90ых (1992-1993) фирмой Silicon Grapgics (сейчас SGI) для мультимедийных компьютеров с ОС Irix. Файловая система была ориентирована на очень большие файлы и файловые системы. Особенностью этой файловой системы является устройство журнала - в журнал пишется часть метаданных самой файловой системы таким образом, что весь процесс восстановления сводится к копированию этих данных из журнала в файловую систему. Размер журнала задается при создании системы, он должен быть не меньше 32 мегабайт; а больше и не надо - такое количество незакрытых транзакций тяжело получить.
Некоторые особенности:
-
Более эффективно работает с большими файлами.
-
Имеет возможность выноса журнала на другой диск, для повышения производительности.
-
Сохраняет данные кэша только при переполнении памяти, а не периодически как остальные.
-
В журнал записываются только мета-данные.
-
Используются B+ trees.
-
Используется логическое журналирование
3.3.4 Файловая система RFS
RFS (RaiserFS) - журналируемая файловая система разработанная Namesys.
Официальная информация на RaiserFS
Некоторые особенности:
-
Более эффективно работает с большим количеством мелких файлов, в плане производительности и эффективности использования дискового пространства.
-
Использует специально оптимизированные b* balanced tree (усовершенствованная версия B+ дерева)
-
Динамически ассигнует i-узлы вместо их статического набора, образующегося при создании "традиционной" файловой системы.
-
Динамические размеры блоков.
3.3.4 Файловая система JFS
JFS (Journaled File System) - журналируемая файловая система разработанная IBM для ОС AIX, но сейчас выпущенная как открытый код.
Официальная информация на Journaled File System Technology for Linux
Некоторые особенности:
-
Журналы JFS соответствуют классической модели транзакций, принятой в базах данных
-
В журнал записываются только мета-данные
-
Размер журнала не больше 32 мегабайт.
-
Асинхронный режим записи в журнал - производится в моменты уменьшения трафика ввода/вывода
-
Используется логическое журналирование.
3.4 Сравнительная таблица некоторых современных файловых систем
|
NTFS |
EXT4 |
RFS |
XFS |
JFS |
|
| Хранение информации о файлах | MFT | inode | inode | inode | inode |
| Максимальный размер раздела |
16 Эбайт |
1 Эбайт |
4 гигаблоков |
16 Эбайт |
32 Пбайт |
| Размеры блоков | от 512 байт до 64 Кбайт | 1 Кбайт - 4 Кбайт | До 64 Кбайт (сейчас фиксированы 4 Кбайт) | от 512 байт до 64 Кбайт | 512/1024/ 2048/4096 байт |
| Максимальное число блоков | 2^48 | 2^32 | 2^32 | ||
| Максимальный размер файла | 2^64 | 16 Тбайт (для 4Кбайт блоков) |
8 Тбайт | 8 Эбайт | 4 Пбайт (250) |
| Максимальная длина имени файла | 255 | 255 | |||
| Журналирование | Да | Да | Да | Да | Да |
| Управление свободными блоками | Нет | На основе битовой карты | B-деревья, индексированные по смещению и по размеру | Дерево+ Binary Buddy | |
| Экстенты для свободного пространства | Нет | Нет | Да | Нет | |
| B-деревья для элементов каталогов | Да | Нет | Как поддерево основного дерева файловой системы | Да | Да |
| B-деревья для адресации блоков файлов | Нет | Внутри основного дерева файловой системы | Да | Да | |
| Экстенты для адресации блоков файлов | Нет | Да (с 4 версии) |
Да | Да | |
| Данные внутри inode (небольшие файлы) | Нет | Да | Да | Нет | |
| Данные симво-льных ссылок внутри inode | Нет | Да | Да | Да | |
| Элементы каталогов внутри inode (небольшие каталоги) | Нет | Да | Да | Да | |
| Динамическое выделение inode/MFT | Да | Нет | Да | Да | Да |
| Структуры управления динамически выделяемыми inode | Нет | Общее B*дерево | B+дерево | B+дерево с непрерывными областями inode | |
| Поддержка разреженных файлов | Да | Нет | Да | Да | Да |
3.5 Файловая система NFS
NFS (Network File System) - сетевая файловая система. Создана для объединения файловых систем по сети.
3.4.1 Архитектура файловой системы NFS
Предоставляется доступ к каталогу (экспортируется) с подкаталогами. Информация об экспортируемых каталогах хранится в /etc/exports. При подключении эти каталоги монтируются к локальной файловой системе.
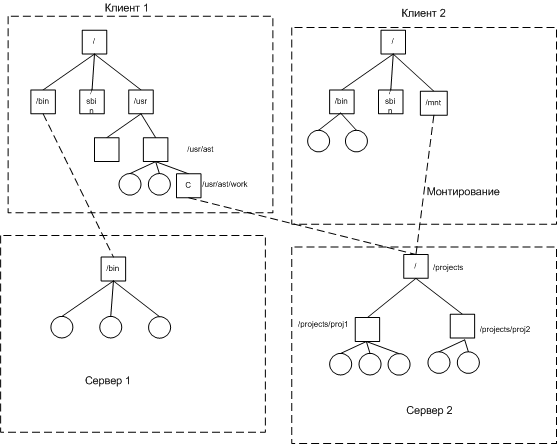
Примеры монтирования удаленных файловых систем
3.4.2 Протоколы файловой системы NFS
Протокол - набор запросов и ответов, клиента и сервера.
Используется два протокола:
-
Протокол управления монтирования каталогов
-
Протокол управления доступа к каталогам и файлам
3.4.3 Реализация файловой системы NFS
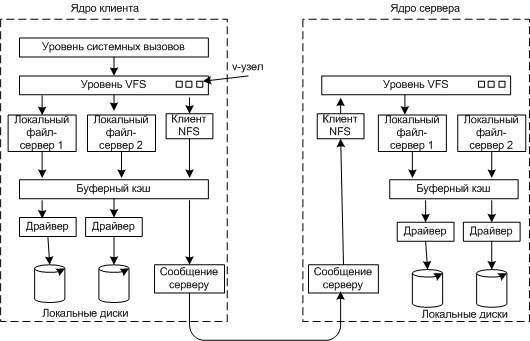
Структура уровней файловой системы NFS
VFS (Virtual File System) - виртуальная файловая система. Необходима для управления таблицей открытых файлов.
Записи для каждого открытого файла называются v-узлами (virtual i-node).
VFS используется не только для NFS, но и для работы инородными файловыми системами (FAT, /proc и т.д.)
Алгоритм работы NFS (рассмотрим последовательность системных вызовов mount, open и read):
-
Вызывается программа mount, ей указывается удаленный каталог и локальный каталог для монтирования.
-
Программа ищет сервер, соединяется с ним.
-
Запрашивает дескриптор каталога.
-
Программа mount обращается к системному вызову mount для монтирования полученного каталога.
-
Ядро формирует v-узел для открытого удаленного каталога.
-
Ядро формирует r-узел (удаленный i-узел) для удаленного каталога в своих внутренних таблицах. В результате v-узел указывает либо на r-узел для удаленного каталога, либо на i-узел одной из локальных файловых систем.
-
Система просит программу клиента NFS открыть файл.
-
Создаются v-узел и r-узел для удаленного файла.
-
Вызывающему процессу выдается дескриптор удаленного файла.
-
Теперь этот процесс может работать с файлом, используя вызов read.